Writing design documents is an established best practice in software engineering. I believe that data and ML projects should make use of design docs as well. Here’s a brief background on design docs and an example for my side project IML Playground.
Background
The idea behind writing design docs is simple: Think before you code. Others have written eloquently about why you should write them. Here are three main benefits from my perspective:
Writing a design doc
- creates a common understanding of the problem to be solved and the project’s goals
- forces the team to think about alternative solutions
- helps making trade-offs explicit and identifying risks early
By design doc, I mean a combination of a functional and a technical specification. In other words: What’s the problem you’re solving and why are you solving it? And how are you planning to solve it, both from the user’s and a technical perspective.
Especially over the past 12 months, working with growing teams, I have come to appreciate the value of design docs for data and ML projects. So much so, that I can quickly feel the difference between the projects, products, or features that started with a good design doc vs. the ones that didn’t. I know, sounds cheesy, but it’s true.
So I decided to make use of design docs for my side projects as well! The remainder of this post is an exemplary design doc for my side project IML Playground with (comments in brackets). IML Playground is not a typical “data and ML project”, but I hope it’ll inspire others to integrate some more design doc goodness into their work.
Example - A Design Doc for my side project “IML Playground”
(In the beginning, I summarize a few pieces of key information so that the reader quickly knows if they are looking at the right document.)
| Application | Description | Author |
|---|---|---|
| IML Playground | A tool to explore and play with interpretable ML methods. | Steffen Bunzel |
Created on: March 28th, 2021, Last updated: April 14th, 2021
Context
(This section is usually not such a long-winded and personal account. Feel free to skip it if you’re not interested in the backstory. But I always give context when writing design docs - e.g., on why the problem is worth solving, where it originated from, or previous efforts made to solve it - before diving into the technical details.)
This document describes the proposed design for a service that makes interpretable machine learning (IML) methods (also referred to as Explainable AI or XAI) accessible. This is a side project and originates from my personal interest in IML. The inspiration for the name IML Playground comes from the TensorFlow Playground.
My interest in IML was sparked in 2018 and Christoph Molnar’s book showed me that there is a wide array of IML methods. Reading through all of these methods made me question how to choose between them and how to decide whether to trust their output.
To answer these questions, I started working on an app to help explore and compare the output of different IML methods on real-world data sets. My initial goal was to enable myself to play with popular IML methods on publicly available data sets that resembled those I encountered in my daily work. As it turned out, the scope quickly grew: I added an option to upload custom data sets and pretrained models. I added model performance evaluation and automatic analysis of feature correlations. I refactored my code to potentially support using (parts of) it as a library.
In the meantime, new IML methods and tools popped up left and right and several tools were published that were similar to what I was working on: Libraries wrapping common interpretability methods combined with ready-to-go interactive dashboards visualizing their outputs: interpret, explainerdashboard, explainX, and shapash are the examples I am aware of and there are probably more.
I am a big fan of these efforts and think they are a great contribution to making IML more accessible and widespread. However, this is not the direction I wanted to take. Instead, I wanted to narrow the scope and focus. This is a side project and I do it for fun. As such, I want it to be a place for me to experiment, learn, and share things I find interesting.
Functional Specification
(This section describes how the final product looks and feels for its users. It’s the foundation for everything that follows since there’s no product without users, regardless of how cool the technical implementation is.)
IML Playground is a tool for technical folks who want to learn more about interpretable ML. As a personal side project, IML Playground should also be fun for its developer. Let’s look at these two main perspectives in more detail:
Scenario 1: Lena (user)
Lena is a junior data scientist. She finished her Ph.D. in Astrophysics (working on black holes and stuff…) 10 months ago and decided to try out what industry has to offer. Ever since, she’s absolutely hooked. There’s so much to learn and she wants to know it all. Coding in Python, implementing data pipelines, building deep learning models - you name it! Last month, while researching modeling techniques for text classification, she stumbled over a tutorial using SHAP to explain Hugging Face Transformer models. Cool! Another world to explore. But where to start?
After a little more research, she finds IML Playground. She scrolls through the examples, plays with the demos, and uses the links to additional resources for deep dives into the illustrated methods. She enjoys the emphasis on working examples / demos over lenghty text and the carefully selected set of references to further reading material. Quickly, she realizes that the code used to create the examples is very easy to follow and provides useful starting points for integrating IML methods into her own work.
Scenario 2: Steffen (developer)
Steffen is a senior data scientist and engineering manager. He’s excited about the recent advances in interpretable ML and has used IML methods on various occasions over the past few years. Due to his management role, developing code becomes an ever smaller part of his day job. To counterbalance this, he started fumbling with coding side projects, most of which didn’t lead anywhere.
IML Playground is different. Steffen enjoys working on the project. It has a clear focus and scope. Whenever Steffen thinks “Hey, wouldn’t X be cool?”, he pauses and refers back to the goals and non-goals he set out for the project making the decision whether to pursue an idea easy. Adding a new feature to IML Playground is straightforward due to its simple design. Managing and maintaining the services running the application creates no overhead for Steffen at all. Wile working on new features, he usually learns something - be it about a IML methods or visualizing their output. From time to time, other data folks share feedback about IML Playground which sometimes triggers interesting discussions about the state and future of IML.
Goals
(A summary of the key goals the service or application is trying to achieve. This can be very detailed and subdivided into multiple categories or a simple bullet list as illustrated here.)
- Create an interactive environment to play with popular IML methods applied to models trained on pre-defined, easy-to-understand publicly available data sets
- Combine working examples with short explanations to give a quick overview of each method
- Provide selected references to additional resources to support the user’s own research
- Keep things simple during development and focused on implementing the IML methods
Non-Goals
(Arguably more important than the goals - laying out what’s not the goal might cause some discussion up front, but will help provide focus later on.)
- Examples for all relevant supervised learning tasks or model classes
- A library to be used by others
- A dashboard visualizing IML methods for custom data sets and models
- An up-to-date collection of all the latest IML methods and tools
Exemplary Output
(Showing concrete examples of what the output might look like helps the reader follow along. Since IML Playground is a web app, I show a mockup of the page here. Not a pretty one, but still. For pure data applications, this section can take a different form, for example a data model of the output to be computed.)
IML Playground is a single page web application. It tells a story from top to bottom and uses a mix of assets (e.g., charts or tables) and text explanations to illustrate common IML methods. Each asset comes with its own little explanatory box in a simple two column layout, like so:
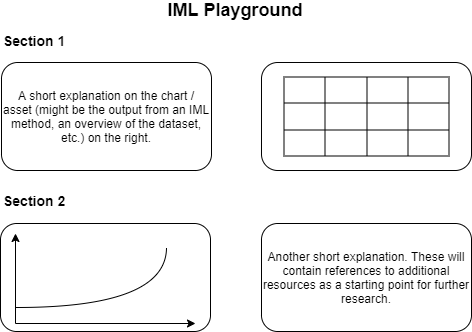
This pattern repeats itself and the box content (asset or text) switches sides with every section to make the whole thing easier to consume.
Proposed Solution
(This is where we start diving into the technical nitty gritty. Before going deep, it’s a good idea to describe the high-level architecture and lay out its pros and cons. After the overview, this section can go into great detail on each technical component, outline concepts for testing and monitoring / alerting, and walk through a roll-out plan. I will focus on the high-level view in this example.)
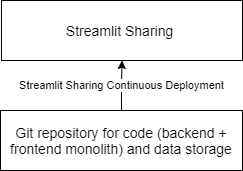
The proposed approach is to choose a technical architecture that is as simple as possible: The application is implemented in a single Python monolith using a Streamlit frontend and in-memory data exchange between backend and frontend. Basically one big spaghetti script. Except that it only contains Streamlit related functionality while code generating models or predictions and applying IML methods to them is organized in modules directly corresponding to the sections in the frontend. Explanations are stored in markdown files separated by section and the example data sets used in the app are made available as csv files directly in the repo.
|-- resources
|-- data
|-- example1.csv
|-- example2.csv
|-- markdown
|-- section1.md
|-- section2.md
|-- iml_playground
|-- section1.py
|-- section2.py
|-- utils.py
|-- app.py
This layout directly integrates with Streamlit Sharing. Sharing is a Streamlit feature (currently invite-only) that offers free deployment and hosting of open-source Streamlit apps.
Pros
- Minimal effort for deployment through Streamlit Sharing’s built-in continuous deployment
- No effort or costs for hosting
- Minimal application complexity through monolith architecture
- Clear focus on method implementation over technical architecture or deployment
Cons
- Full vendor lock-in - the app’s future is at the mercy of Streamlit Sharing
- Strict resource constraints
- Very limited flexibility (Streamlit Sharing defines the execution environment and has requirements towards the app’s layout)
- Limited reusability of the application code
Alternative Solutions
(It’s always a good idea to consider alternatives to the first solution that comes to mind. In particular, I try to think about what a radically different approach would look like. For complex problems with several competing solutions, a detailed comparison in the design doc can also help in choosing the best alternative. I am going to keep this section short and just list possible requirements towards an alternative.)
An alternative that addresses the shortcomings of the proposed solution would need to:
- Be independent of Streamlit Sharing or even Streamlit as a frontend technology altogether
- Be agnostic to the infrastructure provider or service it runs on
- Allow for flexibility in terms of resources and execution environment
- Use an application layout that separates frontend and backend more cleanly such that the backend code could be reused for other purposes and the frontend technology could be replaced
Components of such a solution could be:
- Separate backend and frontend applications that communicate via an API
- All applications are containerized and can be deployed using any of the respective services offered by any of the major cloud providers
- A data storage solution other than “file in a repo” that allows for storing application data (e.g., the feature importance values for a model)
- A provider agnostic CI/CD specification in code, e.g., using GitHub Actions or GitLab CI/CD
- (There’s probably much more to consider and implement which is why I chose the simple solution outlined above)
Success Evaluation
(This could be a separate blog post. In short: Having an idea about how to measure the project’s success early on helps provide focus and accountability.)
Success of this project can be measured in two dimensions: 1. How much fun do I have working on it? 2. How useful is the result to others? Possible metrics for evaluating success are:
| Category | Metric | Description |
|---|---|---|
| Development fun | Number of monthly commits | The more I enjoy working on the project, the more I’ll commit to the IML Playground repo |
| Usefulness | Number of page visits | The more useful the project is, the more it’ll be shared and visited |
| Usefulness | Number of personal interactions | If the project is useful to others, they might be motivated to ask questions, make suggestions, or start discussions |
Open Questions
- How could I support additional example problems? Do I want to do that?
Closing Thoughts
There are many great guidelines, templates, and examples that help you write design docs online. And I hope this post will add to that list. But, while these are useful references, I have learned that every project is slightly different. Don’t consider them strict frameworks to follow meticulously. Instead, take what’s helpful to you and modify it as you see fit.
The key thing is taking the time to think before you code.